
Ramin Nabati
Friday, January 12, 2018
Spacenet 3: Road Network Detection
Background
In this challenge, we were tasked with finding automated methods for extracting map-ready road networks from high-resolution satellite imagery. Moving towards more accurate fully automated extraction of road networks will help bring innovation to computer vision methodologies applied to high-resolution satellite imagery, and ultimately help create better maps where they are needed most. The goal is to extract navigable road networks that represent roads from satellite images.
While Pixel-level F1 score is a widely used segmentation evaluation metric, it is suboptimal for routing applications like road network detection. Because the F1 metric weights each pixel equally, a perfect score is only possible if all pixels are classified correctly as either road or background. With this metric, a brief break in an inferred road (caused for example by an overhanging tree) is lightly penalized while a slight error in road width is penalized heavily. This problem is illustrated in this figure:
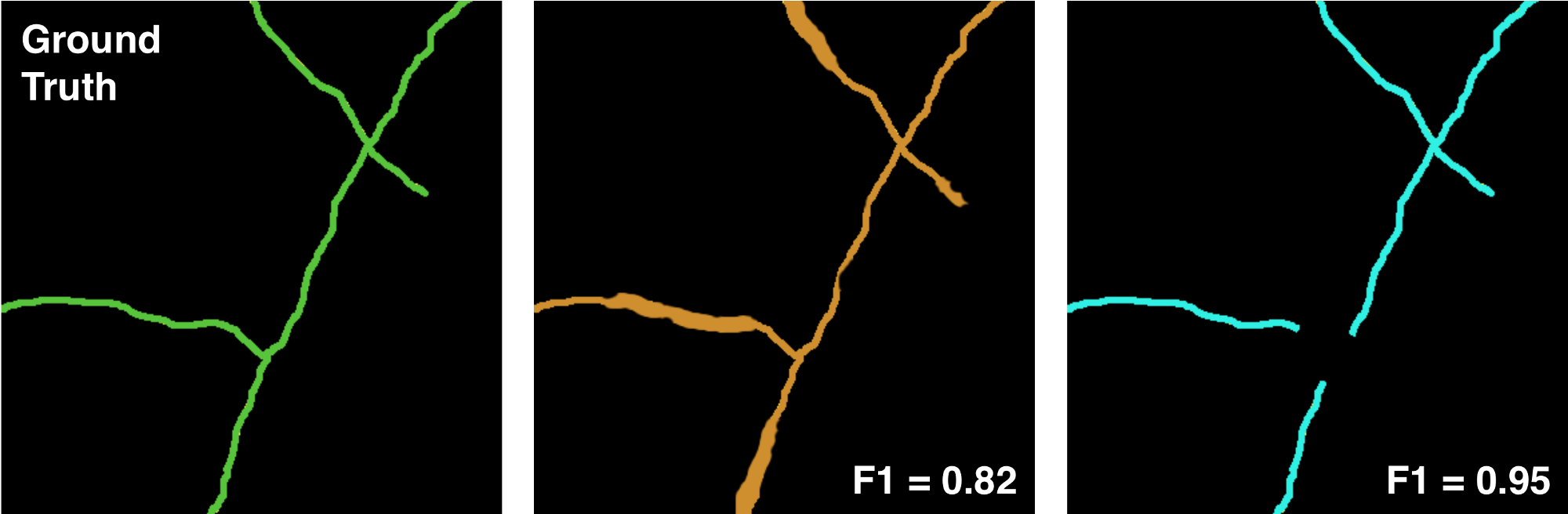
Left: Ground truth road mask in green. Middle: proposal mask in orange, Right: proposal mask in cyan. Credit: [Adam Van Etten](https://medium.com/the-downlinq/spacenet-road-detection-and-routing-challenge-part-i-d4f59d55bfce)
According to the figure, while the orange road proposal achieves a lower F1 score (0.82) compared to the cyan proposal (0.95), it is a better proposal because the cyan road mask misses an important intersection and severs a road. This clearly shows that the pixel-based F1 score is suboptimal in this application.
The Spacenet 3 challenge proposes a graph theoretic metric based upon Dijkstra’s shortest path algorithm, called the Average Path Length Similarity (APLS) metric. APLS sums the differences in optimal path lengths between nodes in the ground truth graph G and the proposal graph G’. More details on this metric is provided here.
Our Solution
We approached the road detection problem in SpacenNet challenge as a semantic segmentation task in computer vision. Our model is based on a variant of U-Net, one of the most successful and popular convolutional neural network architectures for image segmentation. Since we use a image segmentation network to attack this problem, our results are in the form of segmentation masks, which needs to be converted to a line-string graph format. To achieve this, we first extract a binary mask of the detected road network. The result would be something like this:

Binary road map.
Then we skeletonize the segmentation masks to make it as thin as possible. This step helps with converting the mask to nodes and edges in the next step.

Skeletonized road map.
Having lines representing detected roads in the image, the next step is converting the lines to line strings. We simply traverse the lines in each continuous segments and keep adding coordinates to a line string. To fill small gaps in the lines, we introduced memory to our traversing algorithm where the algorithm continues in the previous direction for a certain number of steps even after reaching the end of a line. If another line is found, the two line strings are joined and the traversal continues. Depending on the interval used to record the coordinates while traversing, the resulting line strings can have different number of nodes.